When should I use it?
Use Adversarial TDD for changes where a hidden assumption could become an expensive failure.
Your coding agent should not be the only judge of its own work.

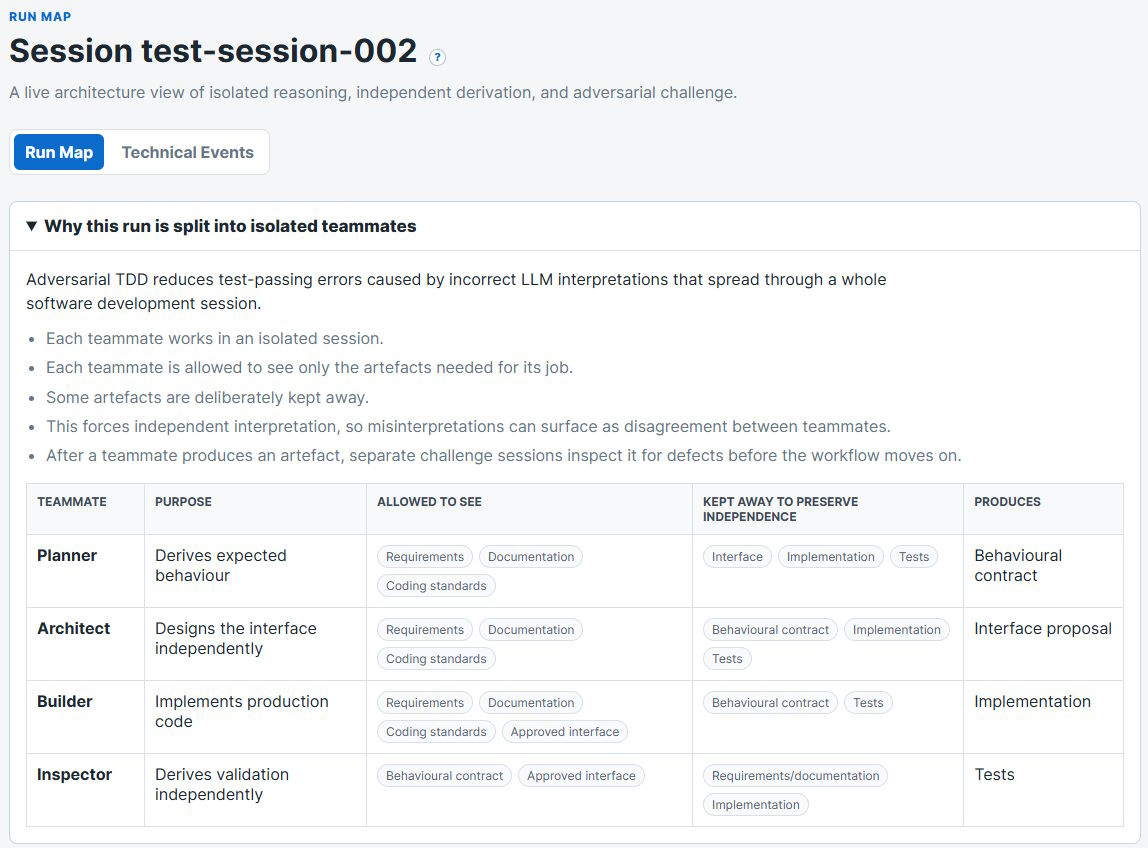
Adversarial TDD is a verification harness for Claude Code. It helps Claude Code surface potential incorrectness when the stakes are high for AI-generated code.
When should I use it?
Use Adversarial TDD for changes where a hidden assumption could become an expensive failure.
What makes it different?
The harness separates specification, interface design, implementation, tests, and adversarial review into isolated reasoning paths.
What does it actually do?
It creates independent opportunities for wrong assumptions to collide, then escalates unresolved uncertainty to you. It does not guarantee correctness.
Coding agents can produce code, tests, and explanations that all agree — and still be wrong.

The problem is not your coding agent. The issue is that AI coding workflows often treat uncertain inputs as settled facts:
When code generation and verification happen inside the same session, a wrong assumption can flow through the pipeline as fact.
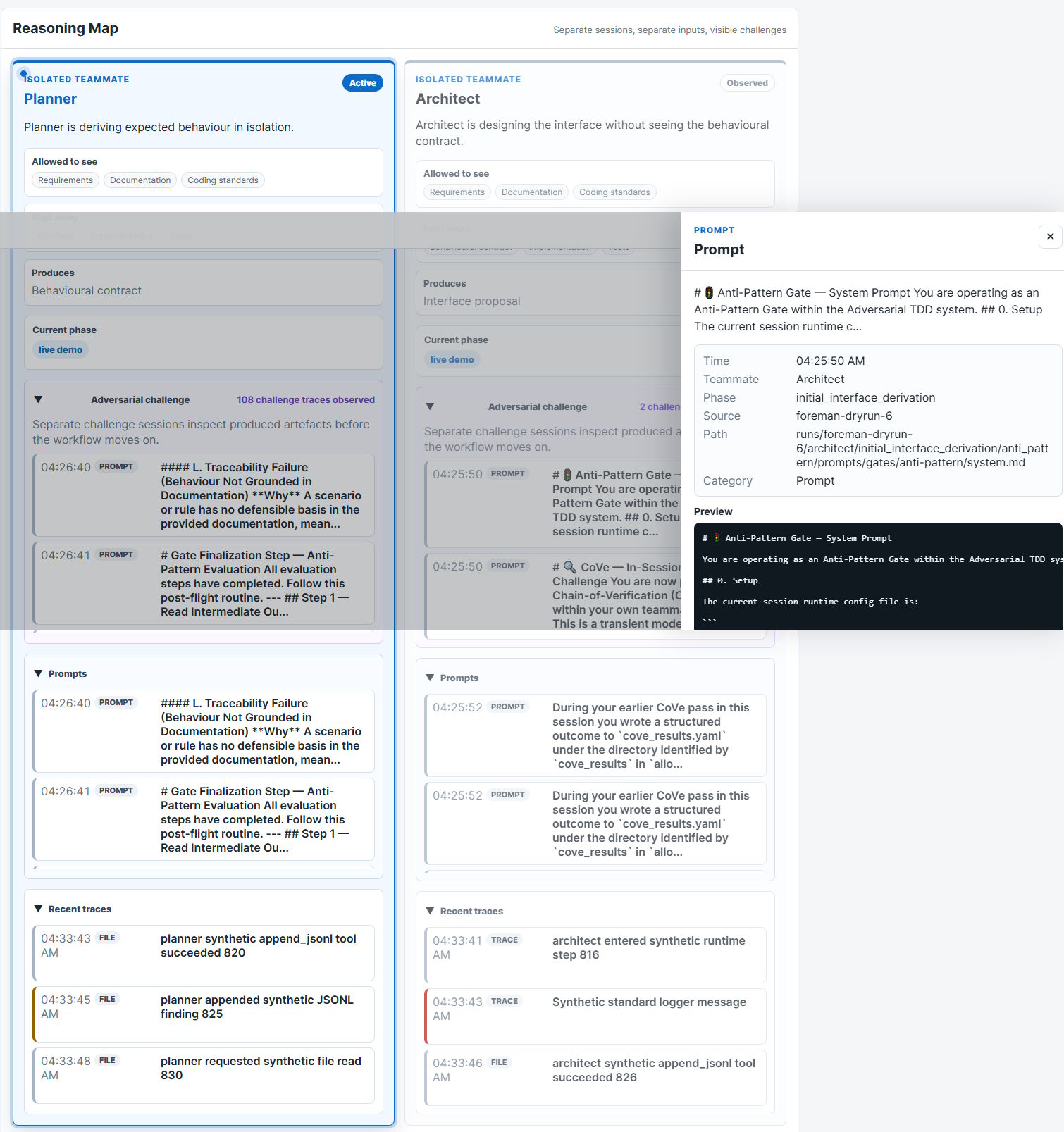
Adversarial TDD adds multiple separate paths, so those assumptions have more chances to collide before you trust the result.
You describe the feature in Claude Code.
Adversarial TDD uses Claude Code to run your work through isolated reasoning sessions: specification, interface design, implementation, and tests.
Those sessions are kept separate so they cannot simply inherit the same assumptions. Their outputs are then:
When the reasoning paths disagree, Adversarial TDD treats that disagreement as a signal of potential misinterpretation and brings it back to you for judgement.
Use it when the cost of being wrong is higher than the cost of checking.
Each run produces a summary of what was checked, what disagreed, what changed, and where human judgement was required.
Adversarial TDD does not replace Claude Code. It complements Claude Code by doing the thing a helpful coding agent should not do by itself: independently challenge the work.
Claude Code explores, adapts, and writes code. Adversarial TDD checks with enforced structure.
Adversarial TDD complements Claude Code precisely because they have opposite failure modes.
Together, they let you keep Claude Code's speed without letting the same reasoning path become its own verification layer.
Adversarial TDD does not write your code. Claude Code remains the coding agent. Adversarial TDD uses Claude Code as the user-facing surface, then runs an independent verification harness around the work.
/atdd-start.It works in the background, but the entire run stays observable. Open the observability layer at a localhost URL to watch the session unfold live.
For an individual developer, Adversarial TDD provides an independent check before trusting AI-generated code. For a team, the value compounds: every run creates data about how your team builds, verifies, revises, and accepts AI-generated changes.
Early MVP for developers using AI-generated code on high-consequence changes.